Indexes
Consider a banking application which uses a database
for storing records. Over a period of time as the no of records increases, the
database performance is no longer satisfactory. One of the first approach to
tackle this issue is database indexing.
Purpose of indexes:
The purpose of creating an index on a particular table
in a database is to make it faster to search through the table and find the row
or rows that we want. Indexes can be created using one or more columns of a
database table, providing the basis for both rapid random lookups and efficient
access of ordered records.
Example:
Consider the below table which is completely unordered.

On execution of below query
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
The problem becomes much adverse as the size of the
table increases.
Querying an unindexed table, if presented visually,
would look like this:

What indexing does is sets up the column to be
searched on in a sorted order to assist in optimizing query performance.
With an index on the company_id column, the
table would, essentially, “look” like this:
|
COMPANY_ID |
UNIT |
UNIT_COST |
|
10 |
12 |
1.15 |
|
10 |
12 |
1.15 |
|
11 |
24 |
1.15 |
|
11 |
24 |
1.15 |
|
12 |
12 |
1.05 |
|
12 |
24 |
1.3 |
|
12 |
12 |
1.05 |
|
14 |
18 |
1.31 |
|
14 |
12 |
1.95 |
|
14 |
24 |
1.05 |
|
16 |
12 |
1.31 |
|
18 |
18 |
1.34 |
|
18 |
6 |
1.34 |
|
18 |
12 |
1.35 |
|
18 |
18 |
1.34 |
|
20 |
6 |
1.31 |
|
21 |
18 |
1.36 |
Now, the database can search for company_id number
18 and return all the requested columns for that row then move on to the next
row. If the next row’s company_id number is also 18 then it
will return the all the columns requested in the query. If the next row’s company_id is
20, the query knows to stop searching and the query will finish.
How does indexing work?
The
database table does not reorder itself every time the query conditions change in
order to optimize the query performance: that would be unrealistic. To enable
this, internally the database creates a data structure to maintain indexes. The
data structure type is very likely a B-Tree which is sortable. When the data
structure is sorted in order it makes our search more efficient for the obvious
reasons we pointed out above.
When the
index creates a data structure on a specific column it is important to note that
no other column is stored in the data structure. Our data structure for the
table above will only contain the the company_id numbers. Units and unit_cost will
not be held in the data structure.
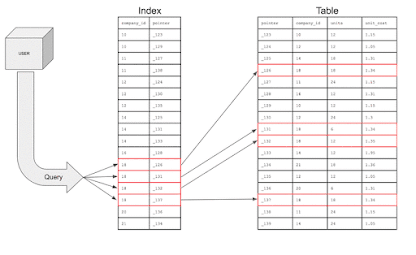
Question arises here, if only the column is contained in the data structure, how does it know about the other columns in the table?
Database
indexes will also store pointers which are simply reference information for the
location of the additional information in memory. Basically, the index holds
the company_id and that particular row’s home address on the memory
disk. The index will actually look like this:

The next question to ask, if we are creating a data structure, does it affect the write performance?
An index can
dramatically speed up data retrieval but may itself be large due to the
additional keys, which slow down data insertion & update. When adding rows
or making updates to existing rows for a table with an active index, we not
only have to write the data but also have to update the index. This will
decrease the write performance. This performance degradation applies to all
insert, update, and delete operations for the table. For this reason, adding
unnecessary indexes on tables should be avoided and indexes that are no longer
used should be removed. To reiterate, adding indexes is about improving the performance
of search queries. If the goal of the database is to provide a data store that
is often written to and rarely read from, in that case, decreasing the
performance of the more common operation, which is writing, is probably not
worth the increase in performance we get from reading.
Indexing strategy guidelines:
Poorly designed SQL indexes and a lack of them are primary sources of
database and application performance issues. Here are a few indexing strategies
that should be considered when indexing tables:
- Avoid
indexing highly used table/columns – The more
indexes on a table the bigger the effect will be on a performance of
Insert, Update, Delete, and Merge statements because all indexes must be
modified appropriately. This means that SQL Server will have to do page
splitting, move data around, and it will have to do that for all affected
indexes by those DML statements
- Use narrow
index keys whenever possible – Keep indexes
narrow, that is, with as few columns as possible. Exact numeric keys are
the most efficient SQL index keys (e.g. integers). These keys require less
disk space and maintenance overhead
- Use
clustered indexes on unique columns – Consider
columns that are unique or contain many distinct values and avoid them for
columns that undergo frequent changes
- Nonclustered
indexes on columns that are frequently searched and/or joined on –
Ensure that nonclustered indexes are put on foreign keys and columns
frequently used in search conditions, such as Where clause that returns
exact matches
- Cover SQL
indexes for big performance gains – Improvements
are attained when the index holds all columns in the query
References:
https://chartio.com/learn/databases/how-does-indexing-work/