Caching
Cache
In computing,
a cache is a hardware or software component that
stores data so that future requests for that data can be served faster. The
data stored in a cache might be the result of an earlier computation or a copy
of data stored elsewhere.
Caching:
Caching is the process of storing data in the cache.
Why to use caching?
Say you're
building a website for users to upload pictures to. At the start, you might
have your application code, web server, and database running on the same as
shown below.

But as you get
more users, the load on your server increases and the application code will
likely take too much of the CPU time. Your solution might be to get more CPU
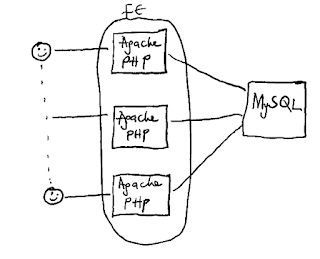
power for your application by running a bunch of frontend servers,
which will host the web server and the application code while connecting to a
single database server as shown below. Connecting to a single database server
gives you the advantage of being certain that all your users will see the same
data, even though their requests are served by different frontend servers.
As your
application grows, the single database server might become overloaded as it can
receive requests from an unlimited number of frontend servers. You may address
this by adding multiple database servers and sharding your data over those servers as shown below. This comes with its challenges—especially around sharding the data
efficiently, managing the membership of the different database servers, and
running distributed transactions—but it could work as a solution to the problem.

But databases
are slow. Reading data from disk can be up to 80x slower than reading data
stored in memory. As your application's user base skyrockets, one way to reduce
this latency in database requests is by adding a cache between your frontend
servers and the database servers. With this setup, read requests will first go
to the cache and only redirect to the database layer when there's a cache miss.

To summarize:
Load balancing
helps you scale horizontally across an ever-increasing number of servers, but
caching will enable you to make vastly better use of the resources you already
have as well as making otherwise unattainable product requirements feasible.
Caches take
advantage of the locality of reference principle: recently requested data is
likely to be requested again.
A cache is like
short-term memory: it has a limited amount of space, but is typically faster
than the original data source and contains the most recently accessed items.

Considerations for using cache?
• Decide when to
use cache: Consider using cache when data is read frequently but modified
infrequently. Since cached data is stored in volatile memory, a cache server is
not ideal for persisting data. For instance, if a cache server restarts, all
the data in memory is lost. Thus, important data should be saved in persistent
data stores.
• Expiration
policy: It is a good practice to implement an expiration policy. Once cached
data is expired, it is removed from the cache. When there is no expiration
policy, cached data will be stored in the memory permanently. It is advisable
not to make the expiration date too short as this will cause the system to
reload data from the database too frequently. Meanwhile, it is advisable not to
make the expiration date too long as the data can become stale.
• Consistency: This involves keeping the data
store and the cache in sync. Inconsistency can happen because data-modifying
operations on the data store and cache are not in a single transaction. When
scaling across multiple regions, maintaining consistency between the data store
and cache is challenging.
• Mitigating
failures: A single cache server represents a potential single point of failure
(SPOF), defined in Wikipedia as follows: “A single point of failure (SPOF) is a
part of a system that, if it fails, will stop the entire system from working”. As a result, multiple cache servers across different data centers are
recommended to avoid SPOF. Another recommended approach is to overprovision the
required memory by certain percentages. This provides a buffer as the memory
usage increases.

• Eviction
Policy: Once the cache is full, any requests to add items to the cache might
cause existing items to be removed. This is called cache eviction.
Least-recently-used (LRU) is the most popular cache eviction policy. Other
eviction policies, such as the Least Frequently Used (LFU) or First in First
Out (FIFO), can be adopted to satisfy different use cases.
Advantages:
Caching improves latency and can reduce the load on our servers and databases.
Levels of Caching:

Application server /Local(private) cache
Placing a cache directly on a request layer node enables the
local storage of response data. Each time a request is made to the service, the
node will quickly return locally cached data if it exists. If it is not in the
cache, the requesting node will fetch the data from the disk. The cache on one
request layer node could also be located both in memory (which is very fast)
and on the node’s local disk (faster than going to network storage).
What happens when you expand this to many nodes? If the
request layer is expanded to multiple nodes, it’s still quite possible to have
each node host its own cache. However, if your load balancer randomly
distributes requests across the nodes, the same request will go to different
nodes, thus increasing cache misses. Two choices for overcoming this hurdle are
global caches and distributed caches.
Content Delivery (or Distribution) Network
(CDN)
CDNs are a kind of cache
that comes into play for sites serving large amounts of static media. In a
typical CDN setup, a request will first ask the CDN for a piece of static
media; the CDN will serve that content if it has it locally available. If it
isn’t available, the CDN will query the back-end servers for the file, cache it
locally, and serve it to the requesting user.
If the system we are
building is not large enough to have its own CDN, we can ease a future
transition by serving the static media off a separate subdomain (e.g., static.yourservice.com)
using a lightweight HTTP server like Nginx, and cut-over the DNS from your
servers to a CDN later.
Other Levels of
caching:
·
Client Caching:
Caches are located on the
client side like OS, Browser, Servers acting as a client for someone like Reverse-Proxy.
·
Web Server Caching
Web servers can also cache
requests, returning responses without having to contact application servers.
·
Database Caching
Database by default
includes some level of caching in default configurations which are optimized
for the generic use case. These configurations can be tweaked to boost the
performance for a specific use case.
Cache eviction policies
Following are some of the
most common cache eviction policies:
- First In First Out
(FIFO): The cache evicts the first block accessed first without any regard
to how often or how many times it was accessed before.
- Last In First Out (LIFO):
The cache evicts the block accessed most recently first without any regard
to how often or how many times it was accessed before.
- Least Recently Used
(LRU): Discards the least recently used items first.
- Most Recently Used (MRU):
Discards, in contrast to LRU, the most recently used items first.
- Least Frequently Used
(LFU): Counts how often an item is needed. Those that are used least often
are discarded first.
- Random Replacement (RR):
Randomly selects a candidate item and discards it to make space when
necessary.
Cache Invalidation:
Since cache data is stored in RAM and RAM size is more limited than
disk. For better utilization of the caches, we need to update the caches in an
optimized way so that it stores more relevant data and remove others. This is
called cache-invalidation. Cache invalidation is a difficult
problem, there is additional complexity associated with when to update the
cache.
There are different cache
update strategy. You should determine the one which works best for you.
.
Write-through cache: Under this scheme, data is written into the cache and the
corresponding database simultaneously. The cached data allows for fast
retrieval and, since the same data gets written in the permanent storage, we
will have complete data consistency between the cache and the storage. Also,
this scheme ensures that nothing will get lost in case of a crash, power
failure, or other system disruptions.
Although, write-through
minimizes the risk of data loss, since every write operation must be done twice
before returning success to the client, this scheme has the disadvantage of
higher latency for write operations.
In write-through cache
application does following:
1.
Application adds
or updates an entry in the cache
2.
Cache synchronously writes
entry to the data store
3.
Cache returns
the entry to the application

Write-around cache: This technique is similar to write-through cache, but data is
written directly to permanent storage, bypassing the cache. This can reduce the
cache being flooded with write operations that will not subsequently be
re-read, but has the disadvantage that a read request for recently written data
will create a “cache miss” and must be read from slower back-end storage and
experience higher latency.
Write-back cache: Under this scheme,
data is written to cache alone, and completion is immediately confirmed to the
client. The write to the permanent storage is done after specified intervals or
under certain conditions. This results in low-latency and high-throughput for
write-intensive applications; however, this speed comes with the risk of data
loss in case of a crash or other adverse event because the only copy of the
written data is in the cache.

In write-behind, the
application does the following:
·
Add/update the
entry in the cache
·
Asynchronously
write an entry to the data store, improving write performance.
It is used in an application
having write-heavy workloads.
Pros:
·
Write-behind
cache improves write performance of the application
Cons:
·
There is a
possibility of data loss if cache goes down before data is written to
the data store.
·
A write-behind
cache is difficult to implement compared to other cache update
strategy.
References:
https://timilearning.com/posts/mit-6.824/lecture-16-memcache-at-facebook/
https://www.youtube.com/watch?v=U3RkDLtS7uY
https://medium.com/system-design-blog/what-is-caching-1492abb92143
https://www.lecloud.net/post/9246290032/scalability-for-dummies-part-3-cache